N + 1 – the main cause of the poor performance of JEE applications coded with JPA
14 December 202101 November 2016 | Software
Introduction
A while ago, when I was still a junior Java developer, one of my colleagues had the ambition to do just OOP, without coding SQL at all. Back then we were using Hibernate ORM 3, which had just been introduced; JPA was not present yet and doing OOP with Hibernate meant using Hibernate Criteria to generate database queries – Oracle Database Server for the project I am discussing. My colleague systematically refused anything that meant SQL, considering that Hibernate ORM was intelligent enough to optimize any query by itself until … Hibernate generated an SQL command of such size that Oracle Database Server refused to execute it (it was a SELECT … WHERE ID IN (….) – with an enormous list of IDs).
In my 18 years as a programmer I have been working on many projects, in different project stages. I have made and seen many mistakes. I have seen many developers getting enthusiastic about JPA (ORMs in general) in the beginning, only to become extremely skeptical later on because „Hibernate is extremely slow” or „JPA barely moves”). The goal of this article is to describe the problem most frequently encountered in JPA, taking JPA 2.1 as a reference point and exemplifying different JPA implementations (Hibernate and EclipseLink).
The examples used in the article can be accessed via Git at: https://github.com/catam1976/JPASamples/tree/master/jpa-issues (build details are provided in the readme saved on GitHub).
The lack of logging on SQL commands generated by ORM
Hard as it might seem, most Java developers fully ignore the monitoring of SQL commands generated by JPA. Almost 2 years ago I reviewed a web application coded in Java 7 with the Spring Framework, JSF 2 and JPA2 (with Hibernate as JPA provider), Maven 3, running on Tomcat 7.
The application was handling member management for an organization. Besides full access to the source code, we got the following hint: „Our application behaves really well in development and very slowly in production, with the real database of almost 1000 members from our organization”.
This is a classic scenario, which I have actually seen many times. After having successfully configured the application on my local machine, the first thing I wanted to check was the number of SQL commands executed for each screen (functionality). To my surprise, about 3000 SQL commands (yes, 3000) were generated for just 10 lines of data displayed in the browser. This number is enormous, so it was obvious why the application was that slow: a wrong usage of the ORM (JPA – Hibernate in that case).
Why hadn’t the programmers that coded that application identified the cause? Was it lack of experience? While this reason may or may not have been real, it is certain that the developers had not used an extremely simple feature offered by JPA providers: the logging of the SQL commands generated – a feature ignored by the majority of programmers, which, combined with a development database populated with very few data, led to very low performance.
Why is this logging necessary?
The answer is extremely simple: logging the SQL commands generated by JPA is the simplest method of monitoring / diagnosing a Java application that uses JPA to access relational database; it is common sense that 10 lines of data on screen does not lead to running thousands of SQL commands; usually, 2-3 SQL command should be enough for the 10 lines of data displayed in the browser.
How is SQL logging for JPA providers done?
While JPA 2.1 came with many new elements, there is still no standard for SQL command logging. For Hibernate, persistence.xml should contain the lines in Figure 1.
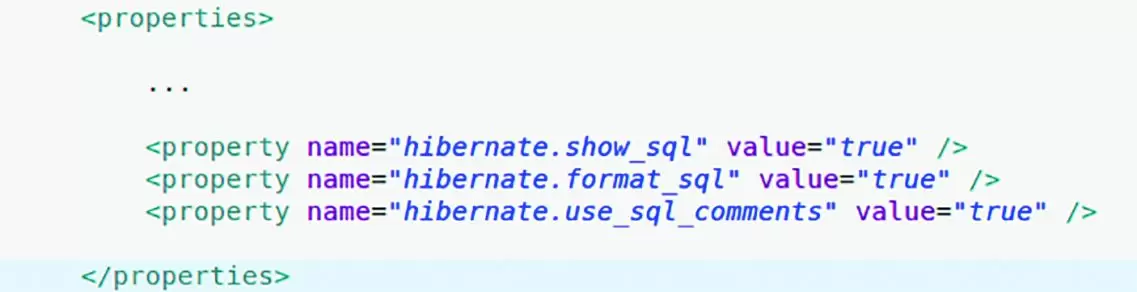
Obviously, the values for those Hibernate specific properties could be filtered with Maven, through a development profile, where all the SQL commands are logged and a production profile, where those commands are not logged, but this is outside our topic.
For EclipseLink, the equivalent settings are those in Figure 2.
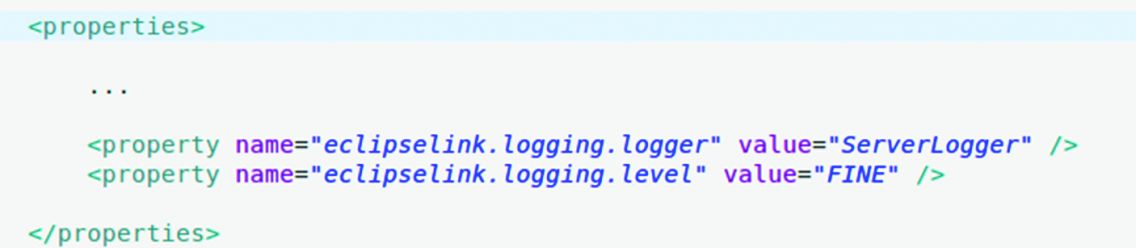
In the examples from GitHub, you can find two persistence.xml files – one for Hibernate (/tools/orm/hibernate/persistence.xml), the other for EclipseLink (/tools/orm/hibernate/eclipseLink/persistence.xml).
Now that we have a way of monitoring SQL commands, we can move on to the most frequently encountered JPA specific problem: the N + 1 problem.
The N + 1 problem, version 1
5 years ago, when I was reviewing an application at a company in Brașov, I found 4-5 lines of Java code that generated hundreds of SQL commands. It seems strange, doesn’t it? You can find below a UML diagram that presents a data model which I will use to explain this N + 1 problem.
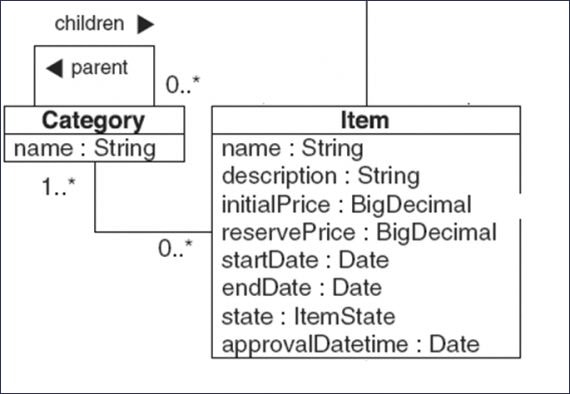
The two entities (Item and Category) in the above diagram are in a many-to-many relationship. For each item, we wish to list the item’s name together with the categories to which it is linked. Figure 3 shows a Java code somewhat similar to the one I saw generating hundreds of lines of SQL code instead of 3-4.
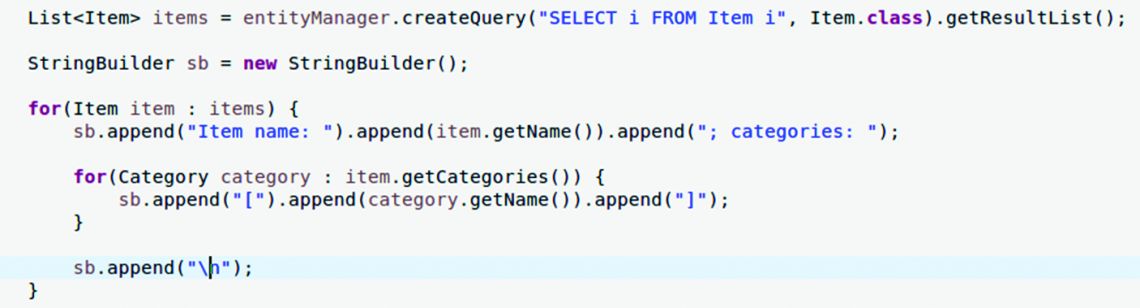
To execute this code, we must execute Boostrap.main method parameterized with doNPlus1FirstCase as the first parameter. Boostrap is the main entry point in the example from GitHub.
As you can see in the log, lots of SQL commands are generated. One to get the items (1) and the rest to get categories (N) – where from the N+1 name. One SQL command run initially leads to at least other N SQL commands (N being the number of records returned by the first command). In other words, the more data there is in the database, the more SQL commands are generated and executed. If there were hundreds of items placed in thousands of categories we would have an extremely low performance for the code above.
Common sense says that a single SQL should be enough. A join between the 2 tables ideally using JPA should do it. I recommend JPA instead of direct SQL, although native queries are sometimes better solutions than JPA-QL. Furthermore, these native queries are easy to integrate into JPAs with @NativeQuery and @SqlResultSetMapping. You can find below my ways of detecting and fixing a N + 1 problem.
The N+1 problem – version 2
Another version of the same type of problem is caused not by Java loops like the ones discussed, but by a wrong modelling of the parent-child relationship between a category and its list of sub-categories. In the example from GIT, one can see in Category.java, the EAGER load of a OneToMany relationship (Figure 4).
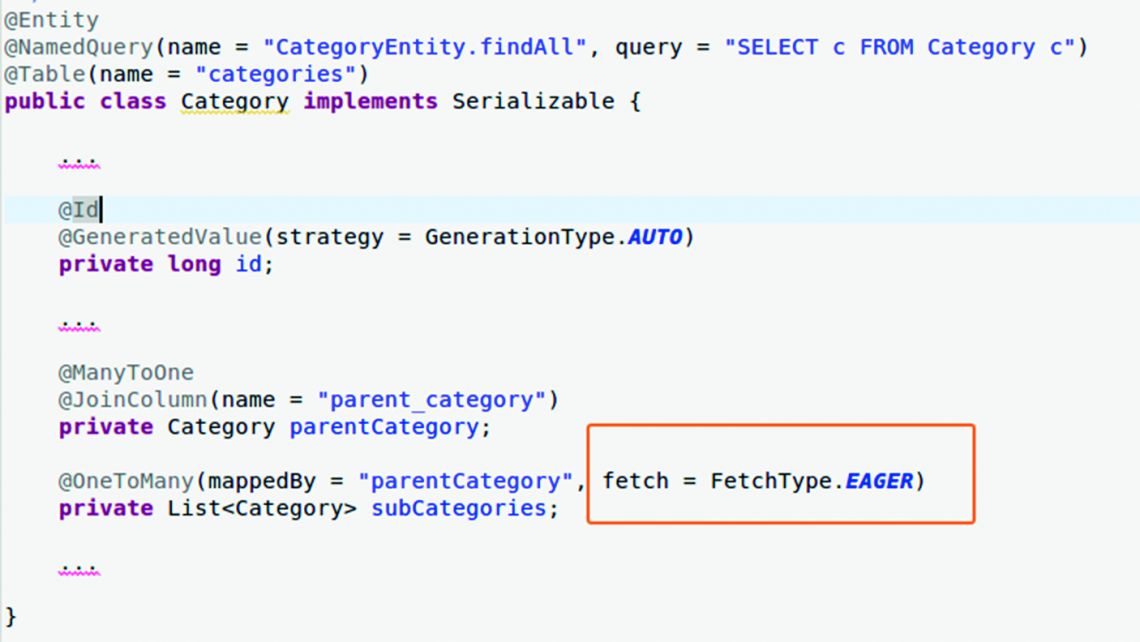
The programmer’s intention was to load the child categories by loading all or one of the categories. The result was a certain type of N + 1 problem, one that resides in a single line of Java code and potentially generates as many SQL commands as the categories defined in the database. The problem is caused by the code within the red border.
To run this code, one must execute the Boostrap.main method parameterized with doNPlus1SecondCase as the first parameter.
As shown in the logs, an SQL was generated to get all the categories; then, for each category from the first result, a SELECT- SQL is executed to get the list of children (Figure 5). Based on common sense, had we chosen the inverse relationship (for a category to get the direct parent), a single SELECT- SQL would have been enough.

Detecting the N+1 problem
The second case is easy to detect: an eager fetch on the OneToMany or ManyToMany relationships. I usually prefer LAZY loading on the OneToOne, ManyToOne (by default, EAGER) and OneToMany, ManyToMany (by default, LAZY).
The first case is a bit more difficult to detect only from the code, as it usually occurs in loops. Logging the SQL command and executing the code step by step can easily lead to the identification of the loop that generates the multitude of SQL commands.
Solving the N + 1 problem
For the second version of the problem, one can eliminate the EAGER load on subCategories and code in Java the grouping of the child-parent categories (with Java Stream API from Java 8, for example). With that EAGER type fetch eliminated, the number of SELECT-SQLs should drop to 1.
For the first version of the N + 1 problem, we must eliminate first the EAGER fetch mentioned above by manually modifying the source code in the Category entity, as shown in Figure 6.

Then, as shown in Figure 7, you can use a join fetch (of course, items will be „doubled”, so you should eliminate the duplicates):
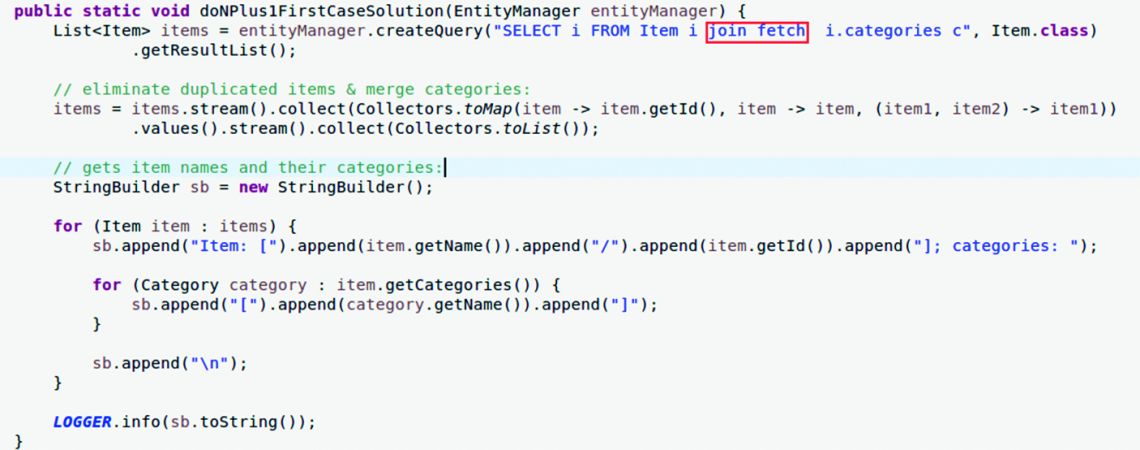
To execute this code, you must execute the Boostrap.main method parameterized doNPlus1FirstCaseSolution as first parameter.
Using Hibernate or EclipseLink as JPA provider, the code from Figure 7 generates a single SQL command, regardless of how many Items or Categories are defined in the database.
Another solution, specific to JPA 2.1, consists of using entity graphs with new annotation @NamedEntityGraph (basically, it can define a graph between JPA entities allowing EAGER fetch).
Conclusion
ORMs are extremely powerful tools if used correctly, constantly monitoring the SQL generated and executed. Every JPA provider has specific mechanisms of generating SQL commands.
No matter what type of relationship there is between two entities, I have always preferred to model them as being with LAZY load, by introducing an EAGER load from JPA-QL or from JPA Criteria. While this relationship, combined with the continuous monitoring of the SQL commands generated does not guarantee success, it can prevent catastrophic situations.
Note: The original version (in Romanian) of the article can be found on Catalin’s personal blog.
About the Author

Catalin



Hi Catalin,
thank you very much for the article it was very helpful, i think there is an error in the article about the default fetch type values for @XXToXX relationships, the JPA 2.1 specification (and JPA 2.2) says :
* @OneToOne : default fetch type ===> EAGER
* @OneToMany : default fetch type ===> LAZY
* @ManyToOne: default fetch type ===> EAGER
* @ManyToMany: default fetch type ===> LAZY
Best Regards.
Hi Andrew,
Indeed, you’ve got stellar eyes. Thank you for indicating the error and your kind thoughts.
Best regards.