REST API in ASP.NET CORE
14 December 202107 February 2018 | Software | Technologies
This article was written by Irina, Microsoft Certified .NET developer working with REST API in ASP.NET Core. To learn more about our know-how and offering in .NET development, see our Custom .NET Development Services.
ASP.NET developers using REST APIs are usually split into 2 categories: the ones that say they work with REST APIs and the ones that claim they are building REST APIs. I am somewhere between them for now, so I say I work with “RESTful-ish” APIs.
To better understand REST API and how to use it in ASP.NET Core, I invite you to get familiar with the following:
- What Is REST?
- The 6 Constraints of REST
- Basic REST API in ASP.NET Core
- HTTP Verbs in ASP.NET Core
- Minimal Status Codes in a REST Architecture
- Headers in a REST Architecture
What is REST in the .NET Framework?
The first thing that comes to mind when thinking about the REST term is API or/and JSON format, but it is not only about that. I assume everybody knows the definition of REST, but what are the concepts and constraints behind it?
The REST term (Representational State Transfer), was introduced in literature by Roy Fielding in 2000 in his dissertation on Architectural Styles and the Design of Network-based Software Architectures. Since then, the term and the process behind it for writing APIs have increased in popularity.
REST is an architectural style, protocol agnostic, for designing loosely coupled applications mostly used over HTTP and often used in the development of web services. It is not a pattern, so think of it as a set of guidelines independent from any programming language or platform. REST has a few constraints that, if implemented correctly, bring a lot of flexibility to your “wannabe” distributed app.
According to the ProgrammableWeb API Directory (the Web journal of APIs), at the end of 2017, 81.53% of the recorded APIs used the REST architectural style.
The 6 Constraints of REST
1. Client-Server
The Client-Server REST constraint states that a client-server architecture is mandatory involved, in the way that a client asks for a resource and a server responds with a resource.
Nowadays, we use this so often, that we forget that there are other types of architectures in the world (for example, the event-based architectures).
The server takes care of under the hood things – such as persisting and retrieving data from the database, and the client simply wants to use those resources to display them in an attractive way. It does this without caring what the data storage is, or how many transformations the data supported until it took the form of a response. This way, the client and the server can evolve separately without affecting each other.
2. Stateless
State, or any form of keeping track of the requests at the server level, should never happen. Everything that the two parties are communicating with each other is should leave no trace.
The Stateless REST constraint says that if there is a trace (such as authentication details or a token of some kind), that trace must be contained in the request because is contextual to that interaction, and the server shouldn’t store anything about it for subsequent communication – it treats each request as new. Because the server doesn’t care and doesn’t want to know about the client (what type of client it is), any potential failure won’t result in a session being out of sync with the client.
Pretty much, the server leaves to the client the burden of managing the state’s complexity and this way it can interact with a higher number of clients, which brings you a little extra scalability.
Surely, there is a content negotiation in place, but that is done through headers, and those headers leave no trace on the server.
3. Cache
Caching is one of the most complex parts of HTTP RFC.
The Cache REST constraint states that the clients can make as many requests as they want, but those requests might be pointless because the data doesn’t change. By using cache, responses from the server have the non-cacheable or cacheable mark and prevent the server from making trips to the database, or process data repeatedly just to send the same response every time.
This way, a client can report itself to the previous answers given by the server and use the data from there until stated otherwise. In other words, your app will have a (perceived) increased performance because it’s not calling the server, or as Fielding says, “the best application performance is obtained by not using the network.”
4. Layered System
The Layered System REST constraint says the client doesn’t know if it’s talking to an intermediate or the real server. The only concern is that it receives an answer, and it doesn’t matter if it’s through a proxy, a gateway or a load balancer.
5. Code on Demand (optional)
Presumably, the server can extend or customize the client functionality. For example, the server can transfer scripts to the client.
The Code on Demand REST constraint established a coupling between the client and the server – the client needs to understand and execute the code it receives.
You can probably understand it more easily by imagining you are downloading a file in your browser, which is part of your app. In this case, your app needs to trust the code it receives, and it may break entirely if the code is bad or not safe.
6. Uniform Interface
The Uniform Interface in REST has 4 sub-constraints and states that everything represents as a resource.
A resource is anything that can have a name, the only restriction is that every resource must have a URL. In the Web world, when you give a URL to something, it automatically turns into a resource. From the client’s perspective, any machine-readable document containing information about a resource is a representation – which in turn, represents a resource state.
Let’s take the following examples:
- https://api.example.com/superheroes
- https://api.example.com/superheroes/1234
a. Identification of Resources
The resources identified in the requests can be different from the server’s representation. This means that no matter what resource returns to the client it is not necessarily a resource with a database representation or a full domain object.
A resource must be ‘addressable’ – to have a URI that never changes, even though the representation changes. If this really happens, the server needs to use the Location header to direct clients to the new URI, along with the correct status code.
b. Manipulation of Resources Through Representations
When a consumer/client doesn’t interact with the server’s resources (domain objects), it doesn’t send queries against a database table. Usually, regardless of the resource ‘exposed’ through the API, the domain object becomes a model that advances further as a response.
When a client wants to update a resource, it updates a portrayal of the resource. This way it avoids strong coupling between the client and the server, and the two entities can evolve separately in a certain measure.
If the URI remains the same, the server implementation and whether it can change independently of the client doesn’t matter anymore.
c. Self-Descriptive Messages
REST forces messages to become self-descriptive. Interaction is stateless between requests and the media types and standard methods indicate meaning, while the responses indicate the cacheability. This way, each request/response includes information so that the receiver can understand it in isolation.
Over HTTP you will need to use the HTTP methods with their real intent: don’t use POST to update a resource, or POST to delete a resource.
If a client doesn’t include the HTTP method in the request, the server doesn’t know how to handle it. The same happens if the response doesn’t include a Content-Type header – the client doesn’t know how to parse the body, spending a lot of time and interaction faulty. Either way, both parties need to provide all the necessary information to each other and process the representations without making any important decisions.
For example, caching a certain resource shouldn’t be a client decision. If it is, what is the basis of the decision? A random timeframe? Or a random algorithm?
Is like going to the store and asking the seller about their current sales offers for a category of products. Because you don’t provide details, the seller asks you about the product you need and you end up spending a lot of time conversating instead of finding out the answer instantly. Isn’t it easier to give to give all the details you can think of about the product you need to the seller in the first place?
d. HATEOAS – Hypermedia as Engine of Application State
The HATEOAS states that we should use links (hypermedia – text with links) to navigate through the application. This means, inside a resource, we should find a links section that enables us to navigate hierarchically.
{
"links": {
"self": { "href": "/superheroes" },
"next": { "href": "/superheroes?page=2" }
}
}
We could also provide links to the HTTP headers. W3C is working on a standard definition for the relation types, so we can use standardized meanings to further help the user.
In other words, Roy Fielding argues that a client shouldn’t know anything about the API, except its initial URI and the appropriate media-types and verbs. From that point on, all the application state transitions will be driven by the client-selection of the received representations from the server, or from the user’s manipulation of them.
Reducing this to the minimum, HATEOAS says that in each response you must include the links for the next request. Basically, you’re telling your clients (let’s say a react/angular app):” here’s your list of URIs, walk through them and display the resources as you wish”. Think of this as you were walking through a maze, with the path already marked for you, and you just follow that mark to reach the exit.
Basic REST API in ASP.NET CORE
Web API offers on the fly all you need to implement Level 2 of the Richardson Maturity Model.
It relies on HTTP verbs and provides a simple way to add controllers to represent resources, but leaves it up to you to do the naming, the routing and to return the right status codes.
Let’s be honest, most of those who tell that their APIs are REST, they surely are at least on level 2 of the Richardson Maturity Model. For level 3, you must put in an extra effort to provide the necessary list of links.
HTTP Verbs in ASP.NET Core
GET
A GET Request doesn’t change anything but retrieves representations of resources. The industry terminology states that a GET request is idempotent, meaning that no matter how many requests you are making to that endpoint, you should get the same results (if the database data doesn’t change).
For any resource representation, you should have two GET Methods in your controller.
Collection Endpoint
http://localhost:52959/api/superheroes
The Collection Endpoint returns a subset of your collection of resources, offering filtering and paging capabilities.
This method shouldn’t be looked at and treated like a GetAll method (from the RPC style approach). What would happen if you have billions of records in your database? Do you really want to return all of them; is that necessary? Just think about how long a potential client will wait for that response.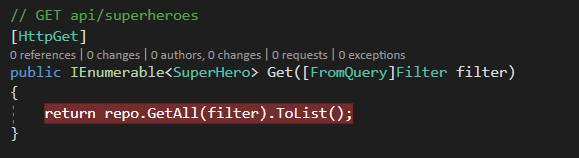
So, in this case, we return nothing if the page is out of bound, or our resources don’t match the filter.
public class Filter
{
private int page;
private int pageSize;
public List<string> Countries { get; set; }
public int PageSize
{
get => pageSize == 0 ? 2 : pageSize;
set => pageSize = value;
}
public int Page
{
get => page == 0 ? 1 : page;
set => this.page = value;
}
}Let’s take the following example:
GET http://localhost:52959/api/superheroes?page=1&pageSize=2
This request will return page 1 with 2 items. But what happens if I want to filter these resources based on their home country or any other criteria? We simply add a list that will bind to the countries in the Filter class and use it as a parameter for the GET request over the collection.
So, the URL with the new filter will look like this:
http://localhost:52959/api/superheroes?page=1&pageSize=2&country=USA
Super easy so far. But what happens if we want to filter on multiple countries and still be REST compliant (considering the same query string parameter is an array or a comma-separated list)?
We will have a problem because currently, WEB API doesn’t bind correctly to your models based on a comma separator or another separator. The only way to make it work is to double or triple your parameter name and values, but this will look very ugly and will exhaust the 2048-character limit of the HTTP request very fast.
In this case, your request will have the following structure:
GET http://localhost:52959/api/superheroes?page=1&pageSize=2&country=USA&country=GB
It will bind correctly but will be counter-intuitive.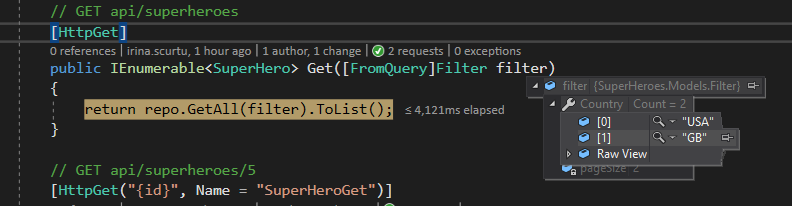
Your target is to have a nice and clean URL like this:
GET http://localhost:52959/api/superheroes?page=1&pageSize=3&country=USA,GB
This way, no matter how many values you need to pass for the same parameter, it will be easy to read.
So, passing multiple values for the same query parameter it’s not an easy job, and it doesn’t work by default in WEB API Core. To accomplish this and make the models bind correctly on the server-side without writing the same parameter over and over, you have two main options:
- Pass the query values as you should and split them on the server, in the controller, because without the split, the Country parameter will bind to “USA, GB” value, and you will always have one item in your list, no matter how many values you add in the request. In this case, you could change your Filter class to have a simple string parameter instead of a List<string>.
- Make a custom attribute that will insert a custom ValueProvider in the execution context, extract the comma separated values and bind them to the model. I recommend this approach because it’s easy to customize and offers the flexibility to apply it only to the controller actions that really need them (mostly GET requests, and maybe not all over the app).
Specific Resource Endpoint
http://localhost:52959/api/superheroes/{id}
// GET api/superheroes/5
[HttpGet("{id}")]
public IActionResult Get(int id)
{
var hero = repo.GetById(id);
if (hero == null)
{
return NotFound();
}
return Ok(hero);
}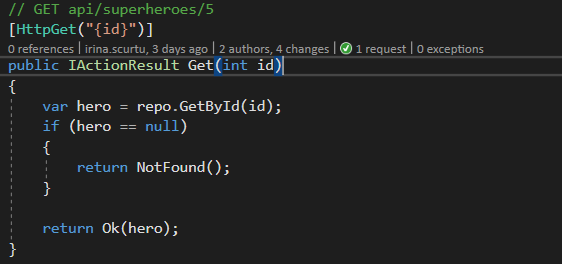
As you can see in the example above, the Specific Resource Endpoint returns a specific item in your collection based on a provided id.
http://localhost:52959/api/superheroes/2
Nested Resources
Resources, no matter the domain, almost always have relationships to other resources (as students to classes, superheroes to outfits, etc). For this, it is not always required to have a separate endpoint, because there might be cases when a resource can only exist in a hierarchical context.
Let’s say you have the following endpoint: http://localhost:52959/api/friends/
Can you tell just by looking at the URL something about the resources? Yes, maybe that will bring a list of friends, but who’s friends? Wouldn’t it be best to call them persons instead of friends?
In this case, http://localhost:52959/api/superheroes/2/friends is more appropriate, because you might want to get a list of friends for a superhero (or for someone in general) not a generic list of friends. This is also more REST friendly just by having that self-descriptive URL.
POST
When you want to add a new item into a collection, you should add a Post Request at the endpoint of the collection. This way, the Post Request will always create a new resource.
POST http://localhost:52959/api/superheroes/
{
"name": "Hulk",
"powers": "Super human force",
"has_cape": false,
"gender": "Male",
"country": "USA"
}This Request will have a 201 Status response code and a response header with a Location URL.

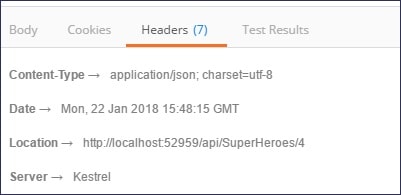
This somehow is compliant with Level 3 of the Richardson Maturity Model.
As a rule, you should avoid using query strings because if you need any/other parameters later, they should fit in the request body.
PUT
The PUT Request makes a full update on the existing resources, overriding the entire resource by adding new properties or removing a few.
The PUT request is always performed at an endpoint that represents a single resource, and not the entire collection. This request is idempotent. When you use the PUT Request, you must include in your request the entire entity, with all the fields it has, and with the intent to replace the entire object.
If you need to update a single property of a resource, you should use the PATCH Request.
PATCH
Although we can find the PATCH Request mentioned for the first time in 2010, by the Internet Engineering Task Force, it is still causing a bit of confusion.
Similar to the PUT request and used for updates, the PATCH request has a major difference: it allows you to include in the request only the fields that need an update (compared to the entire entity required by the PUT Requests). This helps in scenarios where you need to save bandwidth (such as mobile apps that consume API).
Although PUT and PATCH could be used in a similar manner, the purpose is to use them for different sets of operations. Learn more about this here.
DELETE
As the name states, the DELETE Request has the sole purpose to delete a resource. But don’t use Delete for a soft-delete, because HTTP verbs should be used with their real intent.
In this case, to remove a resource, as stated by the Internet Engineering Task Force, in many enterprise applications, the DELETE verb is not used at all due to audit reasons.
Naming
UperCamelCase, lowerCamelCase,compactcase, snake_case(aka kebab-case), Upper_Snake_Case, spinal-case, whatever_you-chooseCase, might give you some overhead if you are writing C# code that needs to send a JSON response in a certain format.
One option might be to decorate your classes with [DataContract] and your members with [DataMember] (the old-fashioned way) or to invent some mystery model binder that does all the work for you – work that might not be so fun to do.
Sometimes there are requirements for a certain naming of the JSON properties that go beyond the readability reasons. Some say that brilliant_no_bugs_code_that_i_wrote is easier to read than brilliantnobugscodethatiwrote because it resembles more the natural language. Some might say that camel case writing is more elegant than seeing a lot of underscores and even the web giants have their preference.
Snake_case: Facebook, Twitter, Dropbox, GitHub, OAuth
Spinal-case: PayPal
camelCase: Google Maps
I’m not talking only about your API endpoints because that is simple – just add a route attribute on your controller and everything is done:
[Route("api/SuperHeroes")]
[Route("api/super-heroes")]
[Route("api/super_heroes")]I’m talking about real data that travels back and forth, in the requests and responses.
In ASP.NET Core you can configure this very easily, without the burden of annotating your class object used to generate responses.
Since everything is highly customizable, you need to add a JSON option in Startup.cs, to tell the pipeline how it should resolve your naming.
services.AddMvc().AddJsonOptions(jo =>
{ jo.SerializerSettings.ContractResolver = new DefaultContractResolver()
{
NamingStrategy = new SnakeCaseNamingStrategy()
};
});
And if this still doesn’t resolve your needs, you could go with camelCase which is the default option.
Minimal Status Codes in a REST Architecture
Currently, there is a list of 41 status codes maintained by The Internet Assigned Numbers Authority (IANA).
There is no need to know them all, especially because some have very limited applicability, but we should know the main 5 categories of status codes that we use most commonly – and even use them in jokes (you might be familiar with the “he’s 404” one). But when it comes to the APIs world, we should pay a special attention to all of them, even to those that are less known.
200 OK
The 200 OK status code stands as a confirmation for a response, along with the entity requested.
As a rule, you should avoid responding with a 200 status code and an error message in the body. An error in processing is still an error and it’s not OK.
201 Created
The client receives a confirmation through the 201 Created status code for the processing of their request and finds out whether their entity is inserted into a collection successfully. It also includes a Location Header with the canonical URL to the new resource.
This status code is important to the client. Think about it: how would you feel if you were to send a package to someone and you’d have no way of knowing that your package reached the destination because you only get a simple “OK – packaged sent” message from the post office? Not good enough, right?
So, use 201 codes when you create a new resource. It’s like saying: mission accomplished, package delivered with success.
204 No Content
The responses with this status code should have no body, meaning that the request has been processed but it has nothing to return. It is often used as a response for a DELETE request.
302 Found
The 302 Found status code informs the client that the resource is available at the URI specified in the Location header, as a result of a post.
406 Not Acceptable
If your API can’t send a representation to the client according to the request’s Accept header, you should use the 406 Not Acceptable status code as a response for a GET request.
When a client has an Accept header of application/xml and you don’t support this format, the response returned should specify that you can’t provide the expected format.
409 Conflict
The 409 Conflict status code informs the client that the action, according to the API semantics, is not successful and can’t get an OK or a Bad Request response.
For example, an API may allow a client to DELETE an empty collection, but send a 409 response if the collection it’s not empty.
In the same way, as a result of a POST request, the client may get a 409 Conflict code if the resource it’s trying to create already exists based on certain properties (such as the same email address for a user creation, etc.). Also, the response body should contain information regarding the source of the conflict.
415 Unsupported Media Type
Whenever a client sends a representation in a media type that can’t be understood by the server you should use the 415 Unsupported Media Type status code. If a server expects application/vnd.collection+json and the client sends application/json or no Content-Type header at all, this is the right response code to use.
In some cases, if the Content-Type is correct but the body doesn’t have the right format, a 400 Bad Request would be better.
Headers in a REST Architecture
ASP.NET Core has JSON as default response format. This means that if a request doesn’t have an Accept header specified, the API will respond with an application/json.
Even so, if the client requests application/xml and the API doesn’t have such kind of formatter, it will still respond with application/json. This is because the framework will try to match the first formatter that can produce a response and it seems that the content-negotiation doesn’t happen at all.
And this is almost true because you need to add an MVC option to enable 406 status codes in Startup.cs, so that for any type you don’t support, the client gets an appropriate response code.
services.AddMvc(options =>
{
options.ReturnHttpNotAcceptable = true;
});
Accept
The Accept header has a major role in content negotiation. Through it, the client tells the server which of the formats it can understand, under the form of MIME types – the mainstream ones or your own custom media types. This is usually used in a GET request.
GET /api/superheroes HTTP/1.1
Accept: application/xml
The request above will receive a 406 Not Acceptable Response with the ReturnHttpNotAcceptable option set on true. Without it, the response will be JSON, no matter what the client Accepts.
[
{
"id": 2,
"name": "BatMan",
"powers": "Fight Evil",
"has_cape": true,
"gender": "Female",
"country": "GB"
},
{
"id": 3,
"name": "Captain America",
"powers": "Fights",
"has_cape": false,
"gender": "Male",
"country": "USA"
}
]
Content-Type
When sending data to the server, this header should specify the type of data in the HTTP body. When the request reaches the server level, if it can’t be processed (or a suitable input formatter is not configured) the server will respond with a 415.
Cache-Control
The Cache-Control header has a major role in the performance perceived by the clients because it basically states how the data should be cached and for how long. Overall, it is a very complex header that has very detailed rules for cache invalidation and works hand in hand with the Expires header.
A caching rule applies to the entire HTTP response, stating with the fact that if a client needs a response, it should search the cached responses before calling the server again.
ETag
Servers should send ETag headers to a GET request whenever possible because it shows a specific version of a representation. Also, the ETag should change when the resource representation changes.
Location
The Location header is relatively new and specifies in the responses the location of a resource after the resource was created, or indicates that a resource was moved in a new place, specified in this header, along with the correct status codes.
This header is relatively new, and it should be used in the responses to specify the location of a resource after that resource it was created or to indicate that a resource has moved in a new place, specified in this header, along with the correct status codes.
For example, for a 301 response code, the Location header should point to the new location of the original resource.
We all want scalable, fast and easy to maintain apps, but we don’t always start coding thinking about how that app will evolve over time. Yes, we code to make the app extensible, easy to change, but scalability is not necessarily a thing we are interested in at the time of coding.
With REST architecture, and by following its principles, you will get a simple, evolvable, visible, maintainable, scalable, reliable and flexible system.
About the Author

Irina



Get Help with REST API in ASP.NET Core
Skilled .NET software developers from Fortech can help you create scalable, performant and reliable software applications that are easy to maintain and empower you with the flexibility to adapt your app as need throughout its complete lifecycle.
Browse Other .NET Development Articles

TagHelpers in ASP.NET Core MVC
TagHepers represent a new mechanism introduced in ASP.NET Core MVC that enable developers to add server-side processing to a regular HTML tag. If used correctly, they can help automate processes, ensure code performance and create consistency throughout the team and the project.

DI or no DI the .NET Framework
From a Dependency Injection (DI) point of view, there are two types of .NET developers. While some recognize the benefits of DI and use dependencies in their projects, many still have a poor understanding of their role. Discover how to identify and leverage the benefits of good dependencies.
Visual Studio Template for Your Microservices Architecture
Visual Studio empowers .NET software developers with the flexibility to create custom templates based on their needs. This is extremely valuable in a project that relies on the microservices architecture, as it enables consistency across the team. Discover a step-by-step tutorial and start creating yours.
Would be nice to see GraphQL vs REST