The Ultimate Guide on How to Make an AI Chatbot
21 December 202128 November 2019 | Software
What is an AI powered chatbot? Which is the best conversational AI platform to build a chatbot? With this new form of interaction on the rise, according to Gartner by 2022, 70% of white-collar workers will interact with conversational platforms daily, answering these questions becomes a top priority for all companies. Fortech has an active internal AI community that strives to keep up with recent progress in Artificial Intelligence.
How Does A Chatbot Work?
A chatbot is simply a software that incorporates artificial intelligence (AI), in order to process the interactions between humans and virtual assistants. At the core of chatbot technology lies natural language processing (NLP). To get a closer look at the recent progress in NLP and conversational AI we set out to implement a chatbot capable to answer any question about our company.
What Do You Need to Create an Artificial Intelligent Chatbot?
Building an intelligent chatbot requires a conversational AI platform and the choices are endless. Given the opportunity to implement a demo for a potential partner, we already had a hands-on with Cognigy, an enterprise conversational automation platform for customer and employee support process automation.
Its main advantage is the friendly development environment which makes it easy for amateurs to quickly implement chatbots in a visual and intuitive way. The conversations are represented as visual flow-charts created with drag-and-drop components. Cognigy has advanced features tailored for enterprise use. As an example, it offers its own cloud for deployment or on-premise solution. However, for the Fortech FAQ artificial intelligent chatbot, we wanted to use an open-source alternative like the RASA framework.
Here is a comparison chart between the two frameworks: Cognigy.AI vs Rasa Stack
RASA is an open-source framework developed in Python and may not be so beginner-friendly as Cognigy, but its AI is more advanced, and the code can be easily customized and extended by developers. For complex conversations, RASA uses ML to learn from many conversational examples called stories that are stored in markdown files. Training from stories requires to configure the RASA engine to use a special policy called “KerasPolicy”.
To achieve our goal, a FAQ chatbot that answers with paragraphs taken from Fortech site, we’ve mapped a large set of predefined questions to the corresponding paragraphs. This can be done using the policy called “MappingPolicy”.
In case a user asks a question that is not in the predefined list the RASA NLU engine uses the so-called word “embeddings” to match the meaning of the question with a predefined one. So, for new but similar questions it will use the same mapped paragraph as the answer. In case of questions with totally new semantics, RASA will report low confidence and can be configured to trigger a default utterance like: “Sorry I cannot answer your question. I am still learning.” To avoid this situation, we’ve decided to try one of the latest state-of-the-art NLP neural network models.
Which Is Better – BERT or the LSTM Neural Network?
BERT model is a complex network based on the powerful transformer architecture. Originally presented in “Attention is all you need” paper, this architecture is a move away from the traditional LSTM based architectures like classic bi-LSTM encoder-decoder with soft attention architecture described here.
The LSTM neural network is a type of recurrent neural network designed to avoid vanishing gradient problem commonly met in RNNs. It can process a long sequence of data items presented one by one to the input. This is perfect for text since the sentences are a sequence of words.
In order to remember past items in the sequence, the LSTM cell uses an internal memory implemented with the help of a recurrent connection. It takes the information from the cell output and redirects it into the network input concatenated with the current item in the sequence. To better understand the idea of recurrent connection you need to think of how our brain takes daily decisions based on current events but also the memory resulted from the output of processing the past series of events.
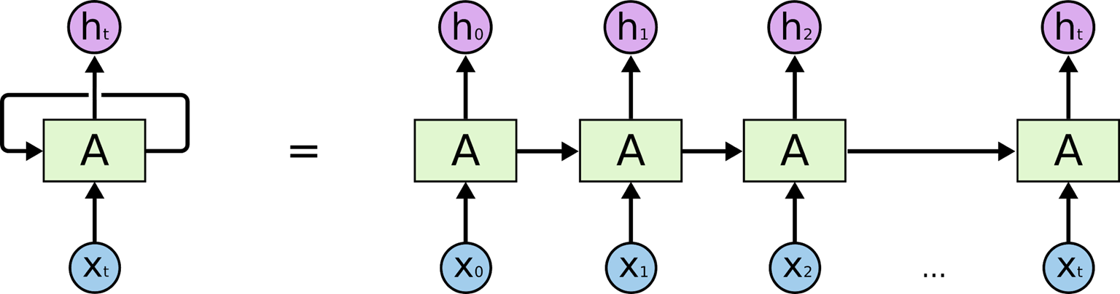
RNN with recurrent link……………………………………………………………………………………………………….Unrolled representation of RNN
Output depends on current input plus previous output (we may say experience). The unrolled representation is equivalent, parameters of each cell are shared.
The access to the LSTM internal memory is controlled by three gates: forget, update and output gate. Behind these gates are layers of neurons that decide what and how much to forget from the memory, what and how much to write into it or to read from it for sending to the output.
The neurons behind the gates take the decision based on the current context which is the current data item in the sequence and the current content of the memory. This gated read-write access to the memory allows the network to learn how to ignore noisy or irrelevant inputs. This is like a basic form of attention used by the human brain to focus on relevant data depending on the context.

LSTM (Long Short-Term Memory) cell is an improved version of RNN cell. The 3 vertical paths are gates with neurons behind them who control access to the recurrent link which is the memory. This intelligent gating access to memory permits longer short-term memory. Source: How Transformers Work.
Legend: 
The main problem with LSTM networks is the sequential nature which requires the processing of the items in the sequence one by one. This makes the network slow at training and inference especially in case of very large networks. Another issue discovered in practice is the inability to handle very long sequences.

“I grew up in France..………………………………………………………………………………………………I speak fluent …”
Predicting the word “french” requires the network to correlate with “France” which is further back in the paragraph and requires a good memory. A disadvantage of RNNs is that the inherent sequential aspect makes them difficult to parallelize. Also, even with improvements from LSTMs or GRUs, long-term dependencies are still hard to catch. Source: How Transformers Work.
The BERT model comes to fix the above issues. This network is based on transformer architecture. At low-level, it consists of many parallel multi-head self-attention modules which are used to learn the meaning of words based on the surrounding context in the sentence. To understand BERT we recommend one of the best tutorials here.
BERT model is trained in two stages called pretraining and finetuning:
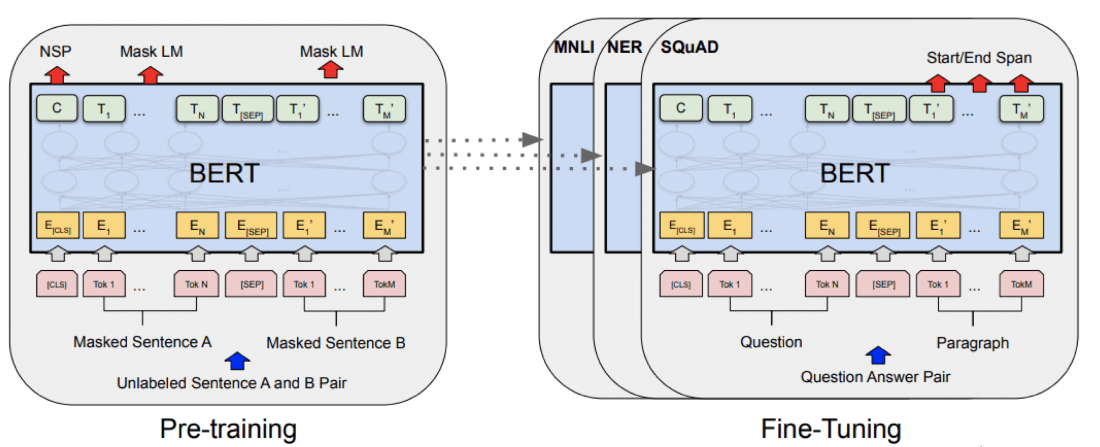
- In the first stage, the model learns to understand the language in an self-supervised way. Self-supervised learning is inspired by the way small children learn on their own with no supervised help from their parents.
The human brain constantly tries to make predictions of unseen data (the future or what we can’t see) based on the known context. In a similar fashion, the BERT model is given huge amounts of data from Wikipedia. About 15% of words are masked out so the network is forced to learn to predict the missing words based on the context of nearby words in the sentence. This way it learns a basic definition of each word in the vocabulary.
- In the second stage, the model is trained in a supervised way on more advanced tasks like question and answering on SQUAD dataset. BERT model is a very powerful universal learner being able to do complex NLP tasks like translating between 100 languages, question, and answering, sentiment analysis, etc. The downside is that it is very large and requires huge computational resources for training.
How to Make an AI Chatbot? | A Step-by-Step Guide
To experiment with the BERT model, we will try a newer library cdQA. We will use the following development tools:
- Miniconda – is a minimal version of Anaconda data science platform which it’s a popular tool for creating isolated virtual environments with the necessary python packages commonly used for machine learning.
- Pycharm – it is a popular IDE for Python language from the same company that created the popular Intellij JAVA IDE. There is a special version of Pycharm with Anaconda plugin which has support for running a project in a Conda environment.
Here are the initial steps to set up the tools and the environment with the libraries needed:
a) Install Miniconda Windows for Python 3.7
b) Install Pycharm Community Edition with Anaconda plugin
Miniconda has its own command-line tool which we will use to set up our virtual environment.
c) First install pip in the base environment:
$ conda install pip
d) Create the project environment with python 3.7:
$ conda create –name Fortech_FAQ_Chatbot python=3.7
e) Activate the Fortech_FAQ_Chatbot conda environment:
$ conda activate Fortech_FAQ_Chatbot
f) Install Rasa framework
$ pip install rasa-x –extra-index-url https://pypi.rasa.com/simple
h) Install cdQA library directly from the source
$ git clone https://github.com/cdqa-suite/cdQA.git
$ cd cdQA
$ pip install -e .
i) As a webchat client, we will use the Scalableminds project which implements the chat window as a React component.
To create and deploy the client artefacts you will need to install yarn application then run in the project folder the commands:
$ yarn install
$ yarn build
The chat component supports also speech recognition.
Here we configured to work with default RASA server port on localhost and enabled speech recognition:
window.chatroom = new window.Chatroom({
host: “http://localhost:5005“,
title: “Chat with Fortech FAQ bot”,
welcomeMessage: “Hi!”,
speechRecognition: “en-US”,
container: document.querySelector(“.chat-container”)
});
To create the actual RASA chatbot server project you need to create new project in Pycharm and connect it with previously created conda environment.
There is also an option also to create conda environment directly from Pycharm.
All this can be controlled from Pycharm->Settings –> Project -> Project Interpreter

There is very good documentation available on the RASA website for the chatbot framework.
You can create an initial RASA project with the following command:
$ rasa init
Our basic chatbot project needs the following files:
The data folder is used to keep in markdown files the intents and stories used for training the NLP model:

In our case, we need to define only a simple intent and story for hello and goodbye. The rest of the conversation will be controlled by the BERT model.
In hello_story.md we map the greetings intent to the answer:
## say hello
* greet
– utter_greet
In hello_bye_nlu.md we define the greet & goodbye intents with various ways to say them:
## intent:greet
– hey there
– Hi
– Hey
– Hi bot
…
## intent:goodbye
– goodbye
– see you around
– Bye
– Bye!
…
In the project root folder we need the following files:

The actions.py file contains custom action methods that can trigger programmatically generated responses.
So here we need to implement our custom action that calls the BERT model to get the answer for any question. We will name this action “action_faq_qa_model”.
For the custom actions RASA has a dedicated server application that can be started from Pycharm terminal with the command:
$ rasa run actions
The config.yml contains RASA engine configuration:
# Configuration for Rasa NLU.
# https://rasa.com/docs/rasa/nlu/components/
language: en
pipeline: supervised_embeddings
# Configuration for Rasa Core.
# https://rasa.com/docs/rasa/core/policies/
policies:
– name: MemoizationPolicy
– name: KerasPolicy
– name: MappingPolicy
– name: “FallbackPolicy”
nlu_threshold: 0.6
core_threshold: 0.5
fallback_action_name: “action_faq_qa_model”
As you see we configured 4 policies. We mainly use “MappingPolicy” to map predefined intents to predefined answers. When the RASA model is unsure of the answer we configured as fallback the custom action for the BERT model.
To trigger the fallback action, we have uncertainty thresholds configured independently for RASA NLU and Core engines:
nlu_threshold: 0.6
core_threshold: 0.5
The “KerasPolicy” is used for RASA model to learn from stories but in our case, we have only a 2 lines story for greeting. Behind the scene, this policy is using LSTM network and embeddings.
“Credentials.yml” and “endponts.yml” files are mainly used to configure security and ports for custom actions server and the chatbot server. They will be created with proper defaults by the initial RASA generated project.
“Domain.yml” file is used to list user intents and the actions triggered by intents or story flows.
As actions, we can have custom actions or template utterances used as answers.
intents:
– greet
– goodbye:
triggers: utter_goodbye
actions:
– utter_greet
– utter_goodbye
– action_faq_qa_model
templates:
utter_greet:
– text: “Hey! How are you? My AI brain will try to answer any question about Fortech company.”
– text: “Hello! Do you have any question about Fortech company?”
– text: “Hi there! I am an AI built to answer your questions about Fortech.”
utter_goodbye:
– text: “Bye.”
– text: “Goodbye.”
As you see we mapped goodbye intent directly to “utter_goodbye” template. In this case the “MappingPolicy” will be used.
We include in the action list our custom action “action_faq_qa_model” and the template utterances for greeting and goodbye.
The template utterances can contain multiple alternate answers for more variation:
utter_goodbye:
– text: “Bye.”
– text: “Goodbye.”
Next, we need to define the custom action in “actions.py”:
class ActionFaq(Action):
def name(self) -> Text:
return “action_faq_qa_model”
def run(self, dispatcher: CollectingDispatcher,
tracker: Tracker,
domain: Dict[Text, Any]) -> List:
…
answer = process_query(tracker.latest_message.get(‘text’), CDQA_PIPELINE)
dispatcher.utter_message(answer)
return[UserUtteranceReverted()]
The custom action is defined as ActionFaq class.
The name() method returns the action name.
The run() method gets the last user question from the tracker object and forwards it to the cdQA pipeline.
We obtain an answer from the BERT model and we dispatch it to the user.
We return UserUtteranceReverted() in order to forget conversational context since we do not need to keep a context for a simple FAQ bot.
For cdQA pipeline to work we will need:
a) we need to download BERT model:
from cdqa.utils.download import download_model
….
download_model(model=”bert-squad_1.1″, dir=”models”)
b) We need to define the knowledge database containing the text from Fortech site. This is a CSV file with 2 columns: paragraph title & paragraph.
title,paragraphs
“Fortech Mastery in software Engineering”,”[‘We help you build quality custom software. Leverage our software development expertise, team extension model and capacity to scale. We have 15+ Years of Experience, 200 Clients and Partners, 700+ Software Engineers.’]”
“What We Do at Fortech”,”[‘We do Custom Software, Software Testing, DevOps.’]”
…
c) we need to initialize & configure cdQA pipeline when our custom action is first called:
global CDQA_PIPELINE
CDQA_PIPELINE = None
if CDQA_PIPELINE is None:
CDQA_PIPELINE = init_cdqa_pipeline(‘cdqa_test/data/Fortech_KB.csv’,‘cdqa_test/models/bert_qa_vCPU-sklearn.joblib’)
d) implement cdQA pipeline initialization and process query methods
from cdqa.pipeline import QAPipeline
from cdqa.utils.filters import filter_paragraphs
def init_cdqa_pipeline(csv_file, model_file) -> QAPipeline:
df = pd.read_csv(csv_file, converters={‘paragraphs’: literal_eval})
df = filter_paragraphs(df, min_length=20)
cdqa_pipeline = QAPipeline(reader= model_file, retriever=“bm25“)
#cdqa_pipeline = QAPipeline(reader=model_file, retriever=”tfidf”)
cdqa_pipeline.fit_retriever(df)
return cdqa_pipeline
def process_query(query_text, pipeline: QAPipeline):
prediction = pipeline.predict(query=query)
return prediction[0]
Our BERT powered chatbot is ready. Let’s start the RASA servers. In a new terminal we start custom actions server:
$ rasa run actions

We open another terminal to run the chatbot server:
$ rasa run -m models –enable-api –cors “*” -t abc –log-file out.log
![]()
![]()
Here is the chatbot in action:

What Issues Do You Face While Building a Conversational AI chatbot?
The cdQA library uses BM25 or TFIDF ranking algorithms to retrieve a shortlist of best matching paragraphs against the query. These algorithms use statistics formulas based on counting word terms present both in query and paragraph. They are commonly used by search engines. The paragraphs found are fed as input to BERT model which predicts the start and the end index of the answer text.
The BERT model input is limited to a maximum of 512 tokens so it cannot accept more than one paragraph. The final answer is chosen based on the confidence level of both the ranking algorithm and the BERT model. We tested the model and found that it gives good answers most of the time. The model can be improved by finetuning on a dataset of questions and answers extracted from our document.
- The biggest problem is the very long inference time of tens of seconds. Even with a GPU the model cannot be used in production because we can have thousands of concurrent requests. There is ongoing work from Google NVIDIA, Facebook and other companies to optimize BERT model architecture to speed up training and inference time. Here are some recent methods to get a leaner faster BERT:
- The model was changed to share parameters and training method was improved: ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
- The large BERT model was distilled into a smaller model using knowledge distillation technique: TinyBERT: Distilling BERT for Natural Language Understanding
- Self-attention module was optimized to run faster on NVIDIA GPUs: Real-Time Natural Language Understanding with BERT Using TensorRT
- Another weakness of the cdQA library is also the paragraph retriever algorithm which uses basic statistics which can be inaccurate and can fetch wrong paragraphs.
- The third issue is that we get as answer only small snippets of text found in the paragraph and not a full sentence which can also use words found in question or new words from the vocabulary.
- The BERT model available with cdQA library was trained on the older SQUAD 1.1 dataset instead of SQUAD 2.0. To do well on SQuAD2.0, models must not only answer questions when possible but also determine when no answer is supported by the paragraph and abstain from answering. There is an ongoing effort from authors of cdQA library to adopt a newer variant of BERT called XLNET which was trained on SQUAD 2.0.
Alternatives to a cdQA Library for Building an AI Chatbot
Besides cdQA library there are other alternatives: AllenNLP and DeepPavlov.
These libraries use older smaller models based on LSTM networks. We tried BiDAF network implemented in AllenNLP combined with cdQA paragraph ranking. The inference was much faster but the results were poor quality compared to BERT.
Some of the big companies published more advanced end-to-end deep learning architectures more suitable for production that combine paragraph ranking and language understanding to locate or even generate answers not found in the context.
An older architecture already used in production by Chinese company Alibaba is described in the paper:
This method uses for paragraph ranking the XGBoost algorithm (boosting decision trees). It uses Bi-LSTM network with self-attention, fusion and pointer networks.
Pointer (generator) networks are based on LSTM cell but they improve on it to make it easier for them to generate novel text. To generate the answer the network can choose to copy words from input (query or paragraph) or use new words from the dictionary. A good article to explain this type of networks can be found here.
Here is another architecture published by Facebook in a very recent paper:
It uses a more advanced curriculum training method and a novel local reasoning layer. This AI is better suited for reading comprehension of books and movie scripts.
A third architecture, which is based on BERT combined with multi-source pointer generator network is presented in the following paper:
The model presented focuses on generating a summary from the question and multiple passages. This serves to cover various answer styles required for real-world applications
We recommend paperswithcode.com to keep up with state-of-the-art papers with code for various types of tasks including Q&A.
In conclusion, there is still ongoing work needed to optimize the BERT models for production and the existing open-source frameworks need to get more mature to include the latest advances. Some of the big companies already use in production advanced AI architectures but for others, it will take some time to benefit from the new research.
In the end, we decided to use only RASA capabilities. We expect, in a few months, better solutions to become available and we will integrate them in time.
About the Author

Alex Movila



Is there an LSTM based model that can achieve similar performance compared to attention-based models like BERT?
Hello Matilda. Thank you for your comment.
There is a new paper that describes a new type of network called SHA-RNN which seems more practical and very close in performance:
Single Headed Attention RNN: Stop Thinking With Your Head.
Please check it here: https://arxiv.org/abs/1911.11423